Contenido Duplicado en SEO: Qué Es y Cómo Solucionarlo

Si estás aquí es porque tu proyecto tiene contenido duplicado.Es un problema muy común que en muchos proyectos puede suponer un problema grande pero no te preocupes, vamos a ver cómo analizarlo y cómo solucionarlo.
¿Qué es el contenido duplicado en SEO?
El contenido duplicado es, básicamente, un texto que aparece en más de una URL dentro de un mismo dominio o incluso entre diferentes dominios. Este texto puede ser idéntico o muy similar. Cuando se habla de contenido duplicado en SEO, nos referimos al texto, títulos o incluso descripciones similares o exactos que se repiten en varias páginas web.
Google y otros motores de búsqueda buscan, por encima de todo, ofrecer la mejor experiencia a los usuarios mostrando contenido relevante y único.
Cuando hay duplicidad, su algoritmo no tiene claro cuál de las páginas debe posicionar; esto puede derivar en que ninguna de ellas reciba la visibilidad óptima.Es una situación que puede tener un impacto significativo, aunque muchas veces pasa desapercibida para administradores y responsables de proyectos digitales.
El contenido duplicado puede generarse por múltiples motivos, desde errores en la gestión de parámetros de URL, sistemas de paginación, versiones con y sin www, problemas con el protocolo http y https, hasta copiar y pegar descripciones de productos de fabricantes.
Es un tema mucho más frecuente de lo que parece, incluso en proyectos gestionados de forma profesional.
¿Por qué el contenido duplicado es negativo para tu proyecto?
El principal problema del contenido duplicado es la confusión que genera en los motores de búsqueda.Google puede no saber qué página indexar o mostrar, lo que reduce la probabilidad de aparecer en las posiciones más competitivas.
Y peor aún, puede que ninguna de las páginas se posicione bien, diluyendo toda la autoridad del dominio entre varias URLs.
Además, cuando el contenido de una web se repite en múltiples URLs, la autoridad del sitio y las señales de relevancia se reparten entre ellas.
Esto causa que cada una tenga menos fuerza frente a la competencia y menos posibilidades de alcanzar el top del buscador. En la práctica, es como intentar empujar varios carros a la vez en diferentes direcciones, se pierde eficiencia y esfuerzo.
Otro aspecto crítico es el de la experiencia de usuario. Cuando los visitantes encuentran varias páginas con el mismo contenido, perciben falta de profesionalidad y posible falta de fiabilidad en la información. Esto puede traducirse en una mayor tasa de rebote y menor tiempo en la web, factores que Google también tiene en cuenta en su algoritmo.
Si tus páginas compiten entre sí por aparecer en ciertas keywords y todas utilizan el mismo contenido, acabarás perjudicando el posicionamiento global del proyecto. En casos muy extremos, el buscador puede llegar a filtrar partes de tu sitio (lo que denomino “páginas canibalizadas”) o, en situaciones delicadas, puede considerarlo una práctica manipulativa y tomar acciones manuales.
Cómo detectar el contenido duplicado
Uno de los pasos más importantes para mantener una estrategia SEO sólida es la detección temprana y precisa del contenido duplicado. Existen múltiples herramientas, pero una de mis preferidas y la que considero más eficiente es Screaming Frog SEO Spider. Esta herramienta te permite rastrear tu sitio como lo haría Google, dimeccionando a fondo cada URL y su contenido asociado.
Paso a paso para detectar duplicidades con Screaming Frog
Lo primero que hago es lanzar un rastreo completo de la web usando Screaming Frog. Simplemente, introduces la URL principal del dominio y dejas que la herramienta recorra todas las páginas accesibles siguiendo enlaces internos.
Es importante que selecciones la siguiente opción en configuración:
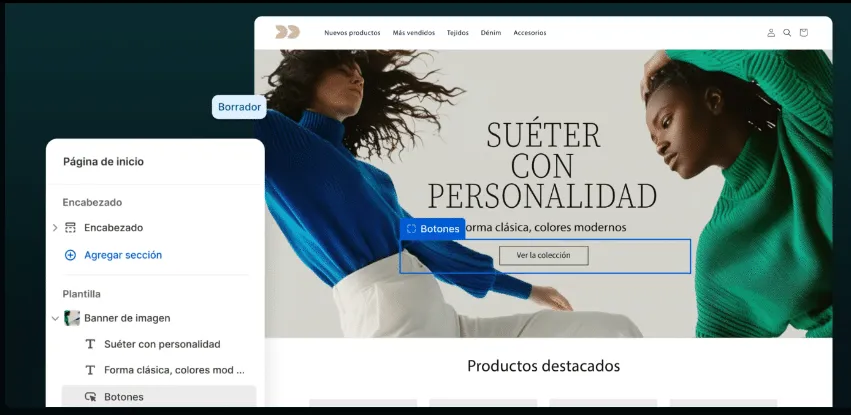
Este proceso es fundamental porque permite localizar absolutamente todas las URLs que pueden contener contenido similar o idéntico. Al terminar el rastreo, dirígete a la pestaña de “Content” o “Contenido” y explora la opción de “Duplicate” para localizar los textos repetidos.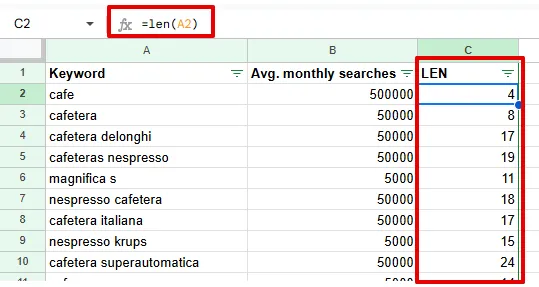
Screaming Frog utiliza un algoritmo de comparación por hashes que identifica bloques de HTML similares, mostrando aquellas URLs que contienen exactamente los mismos textos o fragmentos importantes.
Revisa también titles y descriptions
Un aspecto que muchos pasan por alto es el de las meta etiquetas duplicadas. Al revisar la sección “Meta Descriptions” o “Title Tags” de la propia herramienta, puedes ver rápidamente si existen títulos o descripciones replicadas en varias URLs.
Esta duplicidad es casi igual de negativa, dado que diluye la relevancia y puede desorientar a Google.
Para profundizar, suelo exportar el informe de duplicados y revisarlo detenidamente. No es suficiente con saber cuántas páginas tienen contenido similar, hay que comprender el motivo y el contexto de dicha duplicidad. Muchas veces está relacionada con variaciones de producto, sistemas de filtrados o similares.
Cómo solucionar el contenido duplicado
Solucionar el contenido duplicado requiere un enfoque metódico y personalizado. No existe un remedio universal, pero sí una serie de acciones que, implementadas correctamente, permiten erradicar el problema y evitarlo en el futuro.
Uso de etiquetas canónicas
La primera estrategia que pongo en práctica es la implementación de la etiqueta canonical. Se trata de una indicación HTML que le comunica a Google cuál es la versión principal de un contenido.
Si tienes varias URLs que muestran información similar, esta etiqueta (rel=“canonical”) señala cuál debe tener prioridad en la indexación y transferencia de autoridad.
Para que sea efectivo, reviso que las canonicals apunten a la versión correcta de cada contenido, evitando cadenas de canonicals (es decir, una URL canonicalizada que, a su vez, canonicaliza otra) o autorefencias erróneas. Además, me aseguro de que las páginas excluidas de la indexación no incluyan canonicals inconsistentes que generen confusión al bot de Google.
Enlaces internos y estructuras limpias
Una estructura de enlaces internos bien organizada ayuda a que Google entienda cuál es la jerarquía y relevancia de cada página.
Por eso, reviso el enlazado interno, asegurándome de que las páginas principales reciben más enlaces internos y que las URLs secundarias no compiten entre sí por los mismos términos clave. Esto permite evitar situaciones en las que productos muy similares terminan compitiendo entre sí en vez de reforzarse mutuamente.
Por otro lado, trabajar una estructura de URL limpia elimina parámetros innecesarios y minimiza los riesgos de duplicado. Los problemas más habituales suelen aparecer en webs con filtrados, paginación y e-commerce, donde cada filtro o combinación de parámetros puede generar una URL diferente con el mismo contenido.
En estos casos, utilizo robots. txt para bloquear el rastreo de ciertas combinaciones y elimino páginas innecesarias del sitemap.
Redirecciones 301 y consolidación de versiones
Muchas veces el contenido duplicado responde a diferentes versiones de la misma página accesible desde distintas URLs (por ejemplo, con o sin www, http o https).
Este tipo de duplicidad se soluciona de forma efectiva mediante la configuración de redirecciones 301. Así, cualquier intento de acceso a la versión duplicada se redirige automáticamente a la versión correcta y oficial, consolidando tanto el tráfico como la autoridad SEO.
Antes de implementar este tipo de redirecciones, realizo un inventario de todas las variaciones (incluso mayúsculas y minúsculas) y me aseguro de no crear bucles o redirecciones temporales que compliquen el rastreo del sitio. Una configuración errónea puede tener consecuencias negativas, aumentando el tiempo de carga y dificultando la indexación.
Reescritura y personalización de contenidos
En proyectos con catálogos extensos, como los e-commerce, un error frecuente es duplicar descripciones de productos proporcionadas por fabricantes o utilizar textos idénticos en familias de artículos.
Para resolverlo, trabajo en la creación y personalización del contenido, adaptando descripciones, títulos y atributos para cada producto o categoría.
No se trata solo de evitar la penalización algorítmica, sino de aportar más valor al usuario. Un contenido único y relevante aumenta las probabilidades de que los visitantes encuentren justo la información que necesitan, mejora el engagement y, a la vez, solidifica el posicionamiento a nivel SEO.
Configuración adecuada en plataformas y CMS
Muchos CMS generan automáticamente contenido duplicado: páginas de etiquetas en blogs, versiones imprimibles, archivos de fecha, etc. Una correcta configuración del CMS implica desindexar aquellas secciones que no aportan valor o tener control sobre la generación de URLs.
Además, gestiono los archivos y taxonomías siguiendo siempre las directrices de buenas prácticas, evitando que se indexen rutas que puedan derivar en duplicidad.
Complemento esto con una auditoría periódica y monitorización constante. Las webs cambian, se actualizan y, por tanto, el riesgo de duplicidad es inherente a cualquier sitio. Uso herramientas como Screaming Frog en combinación con Google Search Console y otras utilidades para registrar y solventar incidencias recurrentes de duplicidad conforme evolucionan los proyectos.
Al cuidar todos estos detalles, se maximiza el potencial de cada URL, se favorece el rastreo e indexación de los contenidos realmente importantes y se refuerza la autoridad SEO del dominio, permitiendo que cada proyecto crezca de forma sostenible y rentable en el tiempo.